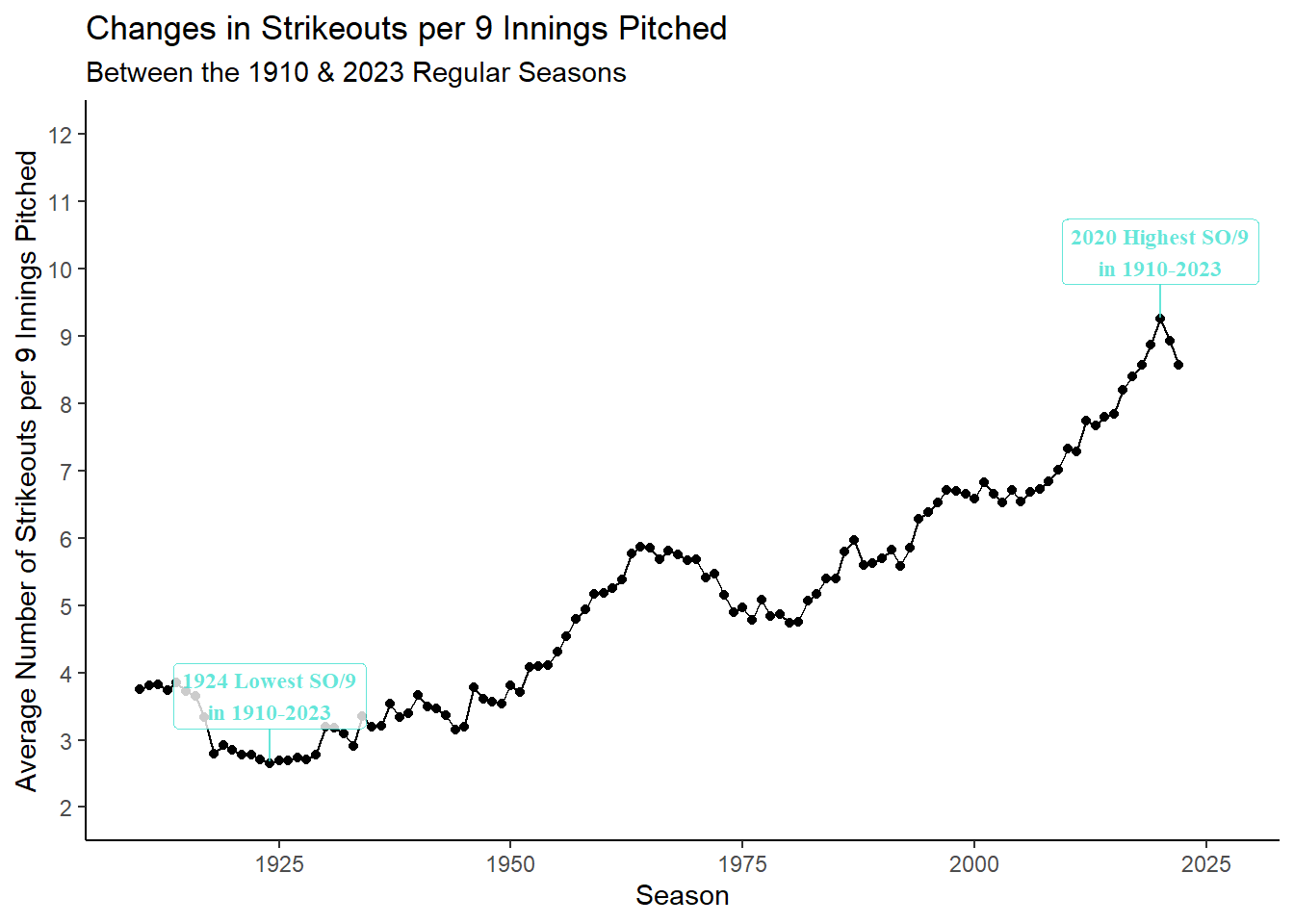
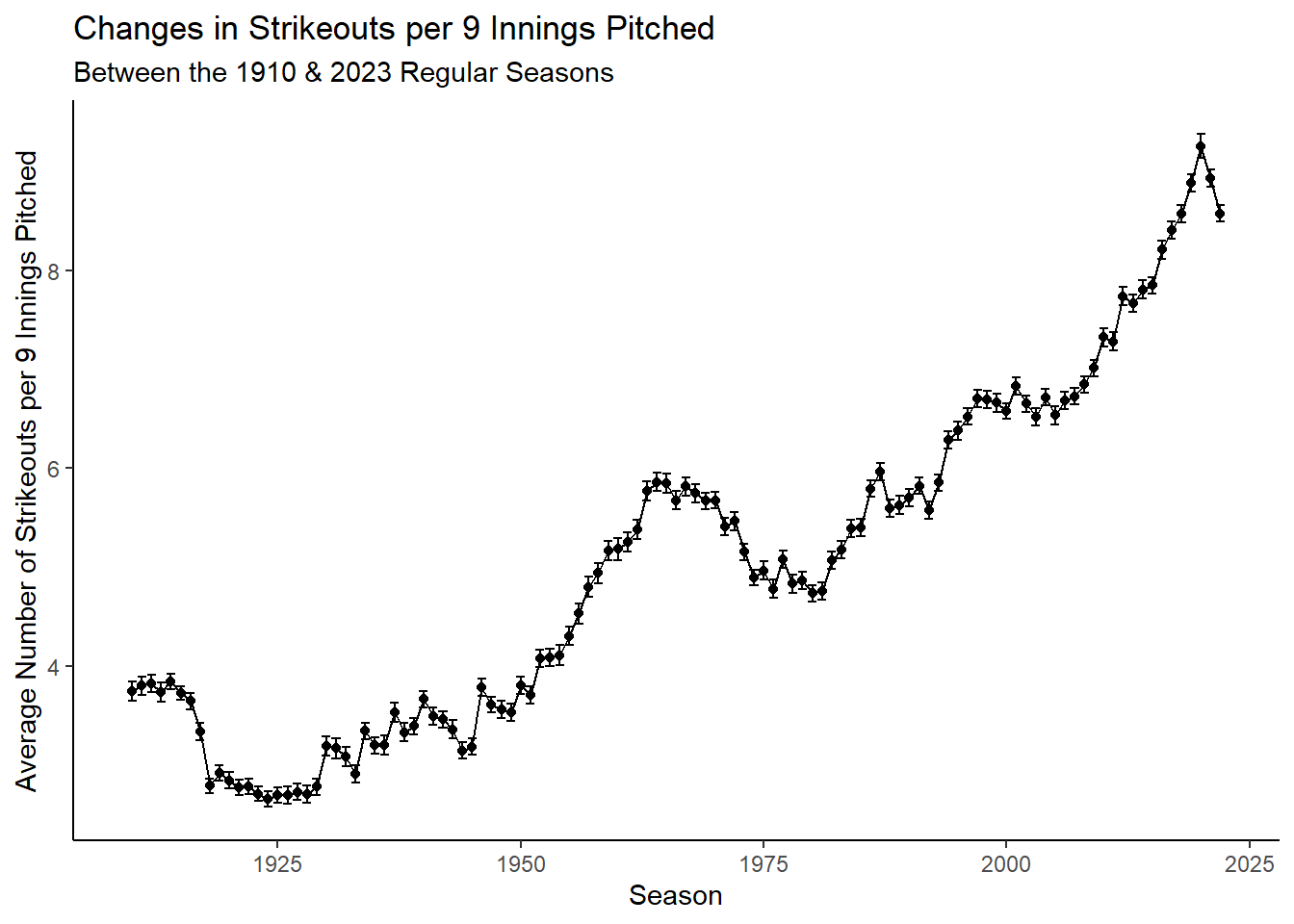
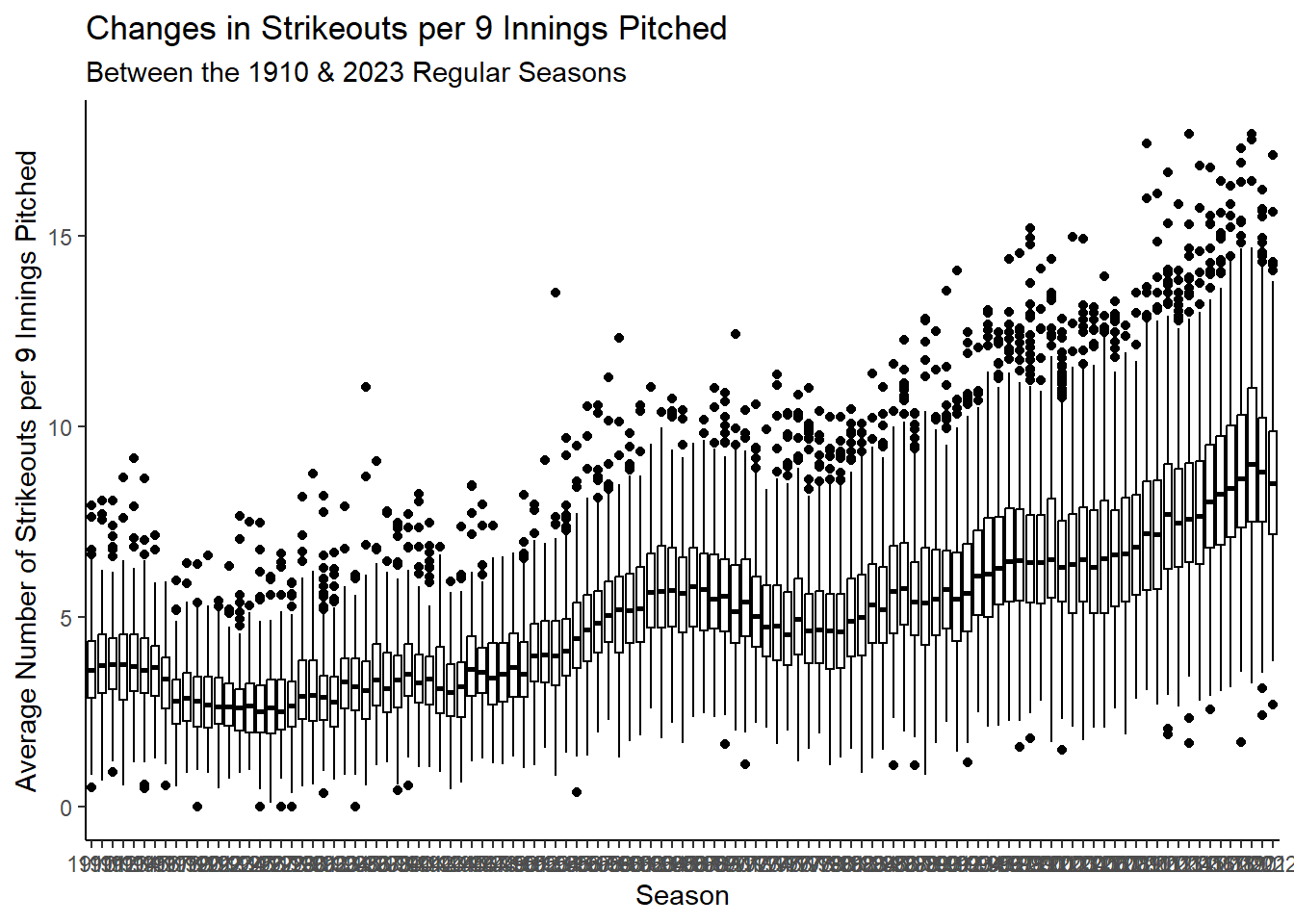
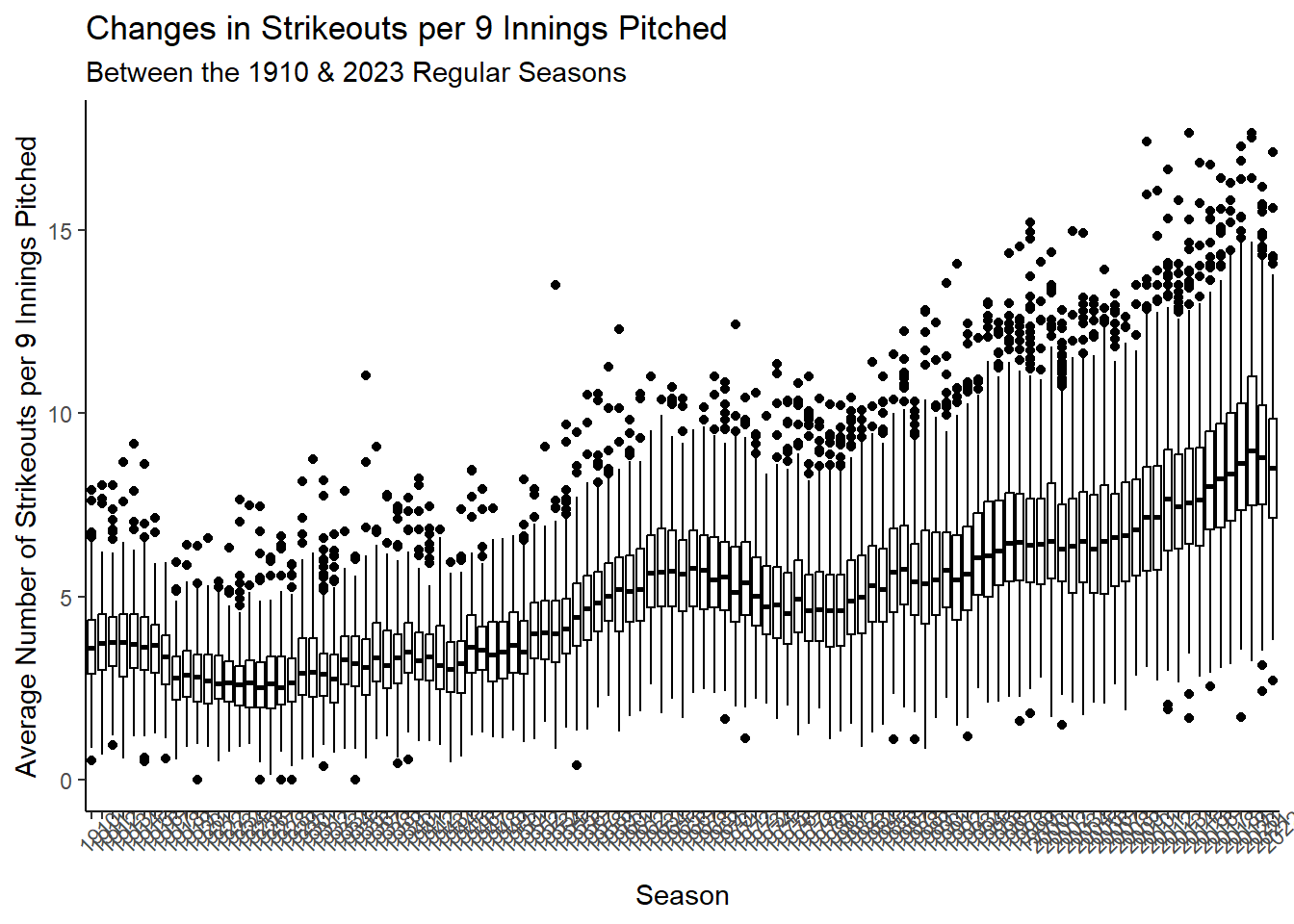
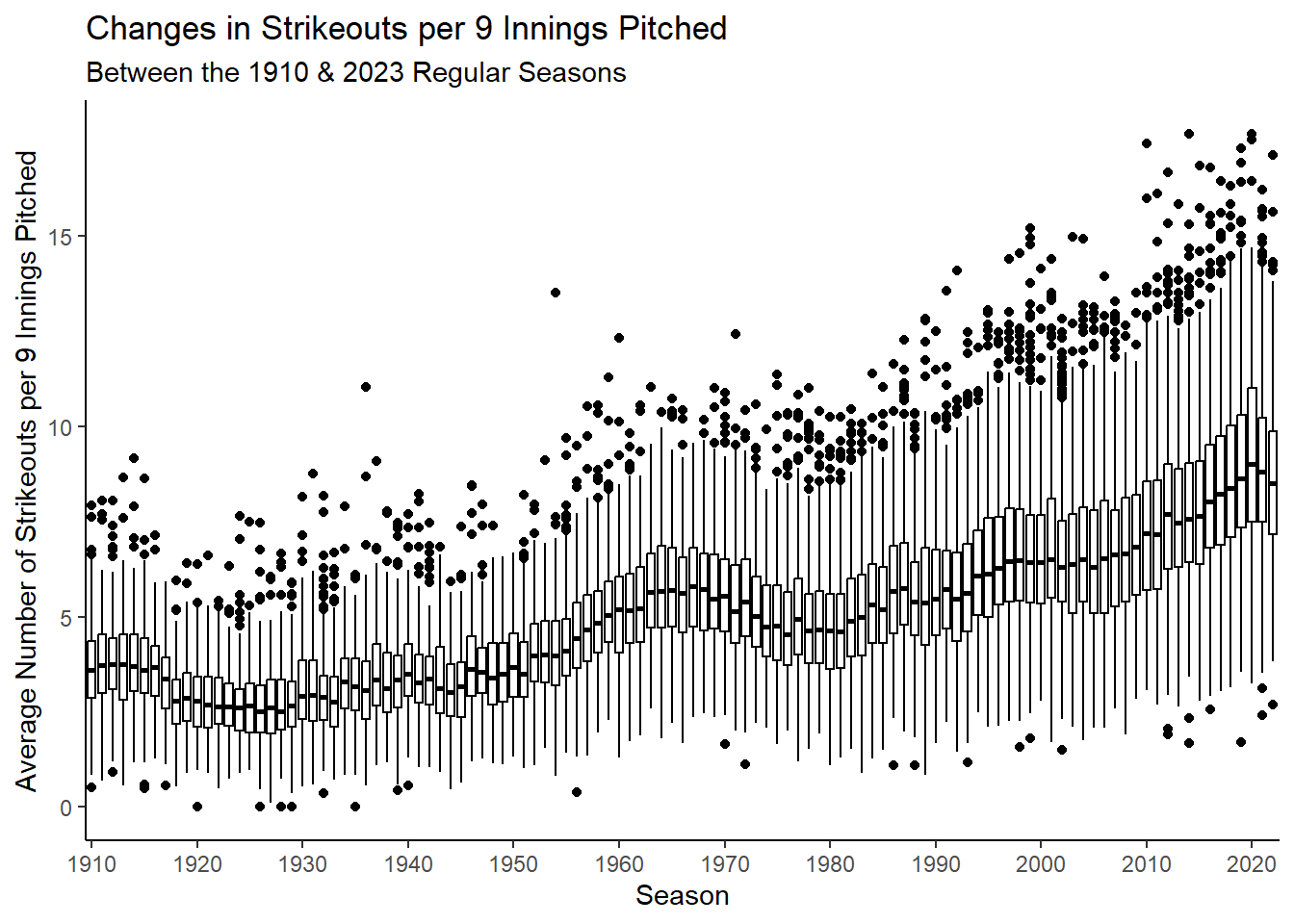
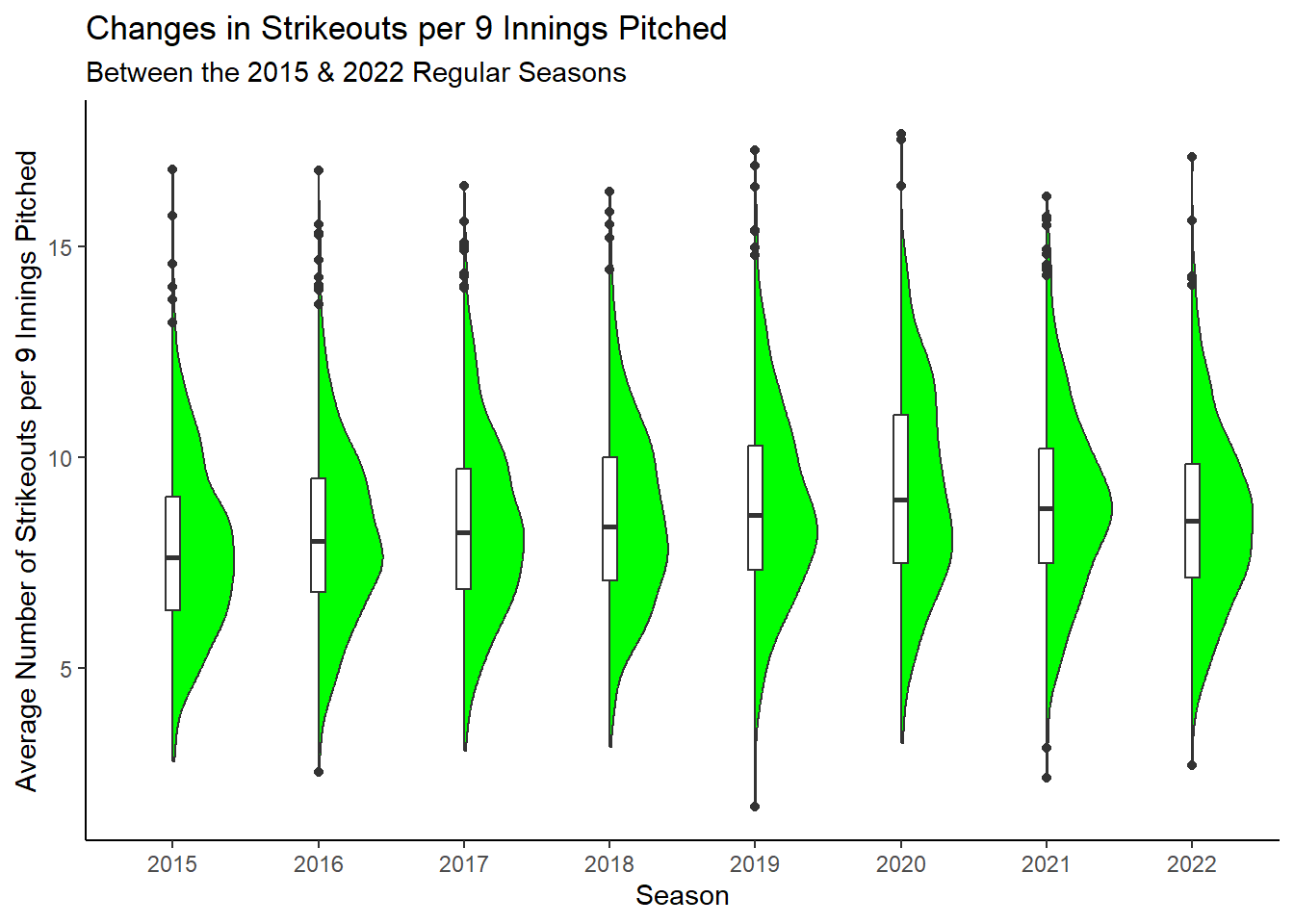
Rows: 34,891
Columns: 31
$ playerID <chr> "adamsba01", "albercy01", "amesre01", "anderwi01", "arellfr01…
$ yearID <int> 1910, 1910, 1910, 1910, 1910, 1910, 1910, 1910, 1910, 1910, 1…
$ stint <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ teamID <fct> PIT, SLN, NY1, CIN, BOS, PHA, SLN, SLA, BRO, CIN, BRO, PHA, C…
$ lgID <fct> NL, NL, NL, NL, AL, AL, NL, AL, NL, NL, NL, AL, NL, AL, AL, N…
$ W <int> 18, 1, 12, 0, 4, 3, 6, 3, 15, 12, 10, 23, 0, 3, 2, 2, 9, 2, 2…
$ L <int> 9, 2, 11, 0, 7, 2, 7, 18, 15, 14, 27, 5, 1, 4, 2, 0, 23, 2, 1…
$ G <int> 34, 4, 33, 7, 18, 15, 26, 34, 35, 35, 44, 30, 12, 13, 6, 19, …
$ GS <int> 30, 3, 23, 2, 13, 3, 11, 20, 30, 26, 36, 28, 2, 8, 5, 5, 29, …
$ CG <int> 16, 2, 13, 0, 2, 2, 5, 13, 25, 11, 25, 25, 0, 2, 4, 2, 16, 2,…
$ SHO <int> 3, 0, 3, 0, 0, 0, 0, 0, 2, 2, 4, 3, 0, 0, 1, 0, 1, 0, 6, 0, 0…
$ SV <int> 0, 0, 0, 0, 0, 2, 2, 0, 1, 0, 1, 0, 0, 0, 0, 0, 2, 3, 7, 0, 0…
$ IPouts <int> 735, 83, 571, 52, 300, 171, 348, 577, 815, 643, 930, 750, 114…
$ H <int> 217, 35, 161, 16, 106, 53, 117, 186, 267, 193, 267, 182, 44, …
$ ER <int> 61, 19, 47, 9, 32, 17, 39, 71, 87, 73, 91, 44, 20, 22, 14, 19…
$ HR <int> 4, 1, 3, 0, 1, 0, 4, 2, 2, 3, 4, 1, 1, 0, 0, 2, 4, 0, 3, 1, 0…
$ BB <int> 60, 20, 63, 17, 24, 23, 53, 97, 107, 94, 82, 47, 23, 32, 12, …
$ SO <int> 101, 10, 94, 11, 33, 29, 41, 90, 87, 93, 102, 155, 15, 24, 25…
$ BAOpp <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ ERA <dbl> 2.24, 6.18, 2.22, 4.67, 2.88, 2.68, 3.03, 3.32, 2.88, 3.07, 2…
$ IBB <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ WP <int> 1, 1, 9, 1, 3, 0, 3, 8, 3, 7, 1, 7, 1, 1, 1, 0, 9, 1, 6, 4, 3…
$ HBP <int> 6, 0, 6, 1, 3, 1, 2, 10, 6, 7, 4, 10, 1, 3, 4, 3, 4, 0, 4, 2,…
$ BK <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0…
$ BFP <int> 971, 126, 747, 80, 401, 233, 497, 816, 1083, 884, 1194, 936, …
$ GF <int> 3, 1, 5, 5, 5, 9, 11, 9, 4, 6, 7, 2, 10, 4, 1, 13, 11, 5, 14,…
$ R <int> 95, 22, 78, 15, 41, 33, 55, 133, 105, 101, 127, 63, 34, 25, 1…
$ SH <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ SF <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ GIDP <int> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
$ SO9 <dbl> 3.710204, 3.253012, 4.444834, 5.711538, 2.970000, 4.578947, 3…